
geralt / Pixabay
翻訳されたコンテンツが日本語として不自然に感じるとき、「どうせ翻訳ソフト使って訳したんじゃないの~?」なんてことを言う人がいます。
「翻訳ソフト」が何を指すのか?という点は置いておいて、結論から言います。
実はそれ、かなり当たっているかもしれません。
コンピュータ支援翻訳(CAT)という概念が登場して久しい翻訳業界
翻訳業界には、「Computer-aided translation」または「Computer-assisted translation」(CAT)と呼ばれる考え方があります。
これは、おおまかには「コンピュータ技術を使用して、人が翻訳する効率を高めたりプロセスを合理化したりしよう」という考え方です。
そして実際に翻訳者、そして翻訳業界向けに、この考えに基づいてさまざまなソフトウェアが開発され、実用化されています。
そのようなソフトウェアのたぐいは総称してCATツールとか翻訳支援ツールと呼ばれますが、それらに搭載される機能のうち、最もメジャーなのは次の2種類です。
- Translation Memory(翻訳メモリ、TM):翻訳者が作成した訳文について、原文と訳文のペアをデータベースに登録し、その情報を再利用することで効率化を図る。訳文自体はあくまで翻訳者が作成する。
- Machine Translation(機械翻訳、MT):原文を解析し、ソフトウェアによって生成された訳文を出力する。
一般にこの記事の冒頭のように「翻訳ソフト」と言ったとき、頭に思い浮かべているのは機械翻訳(MT)の方だと思いますが、翻訳業界で比較的よく使用されているのは、翻訳メモリ(TM)の機能を搭載したツールです。
翻訳メモリについては、10年以上前から実用化された製品がすでに存在していました。
翻訳分野や翻訳会社によってはまったく使用しない、というところもあるとは思いますが、多くの翻訳分野で徐々に普及が進み、現在ではごく普通に使用されています。
特にIT関連の翻訳をやっていると持っていて当たり前、使えて当たり前、むしろ持っていないと案件の受注さえ困難なものとなっています。
しかし、まったく触ったことがないとどんなものかわかりません。まずは具体的な使用例で翻訳メモリについて説明したいと思います。
翻訳メモリの使用例
たとえば、下のような内容の英文が書かれたWordファイルがあったとして、翻訳メモリを使用してこのファイルを訳す場合を説明したいと思います。
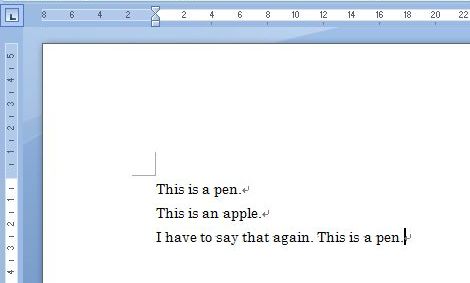
なお、以下で使用しているのは、翻訳支援ツールのなかでもっともメジャーと思われるSDL Trados Studio(翻訳メモリ機能を搭載した製品)です。
作業画面
まず作業用の画面ですが、下の図の説明のとおり、基本的には大きく3つの部分に分かれます。
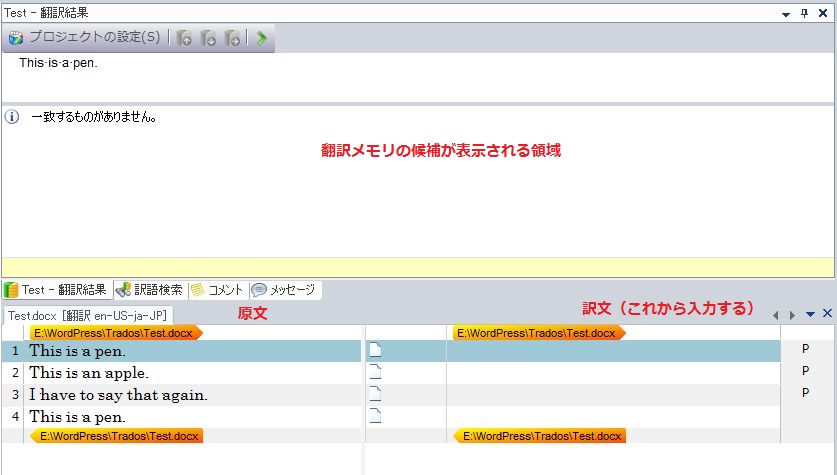
上半分の翻訳メモリの内容が示される部分、左下半分の原文、そしてこれから翻訳者が訳文を入力していく右下半分です。
上の図は最初のセンテンス「This is a pen.」を訳すところですが、現在、翻訳メモリには何も入っていないので画面の上半分(翻訳メモリの内容表示部分)には何も表示されていません。
1行目の翻訳
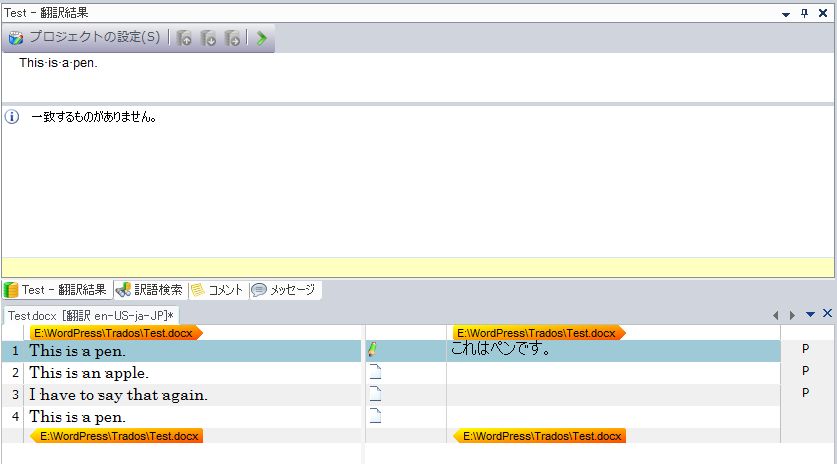
ここで最初の訳文、「これはペンです。」を入力して、訳文を確定すると、次のような処理が行われます。
- 翻訳メモリに「This is a pen.」と「これはペンです。」という原文・訳文のペアが自動的に追加される。
- 以降、同じ原文が出てきたら、翻訳メモリに登録したものと同じ訳文を自動的に適用する。
- 以降の作業で、類似した原文が出現し、この原文・訳文ペアが再利用できそうなら候補としてこのペアを翻訳メモリの内容として表示する。
上記処理が行われるため、2番目のセンテンス「This is an apple.」を訳す場合には、次のような画面になります。
2行目の翻訳
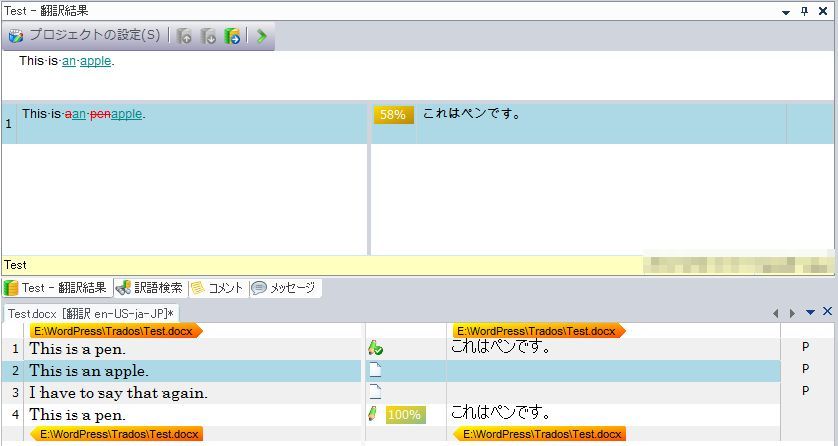
この図は、カーソルが2行目にあり、2番目のセンテンスを訳そうとしているところです。
先ほどの説明どおり、1行目の作業で原文・訳文のペア(This is a pen.=これはペンです。)が翻訳メモリに登録されているため、次の処理が行われています。
- 4行目に100%一致するセンテンス(This is a pen.)があるため、翻訳メモリの訳文を自動的に適用している→翻訳者は訳文を入力しなくて済みます。
- 2行目を訳すために再利用可能な翻訳メモリの内容として、さきほど登録したメモリの内容(This is a pen.=これはペンです。)を表示している→翻訳者は訳文を部分的に利用して訳文を作成できます。
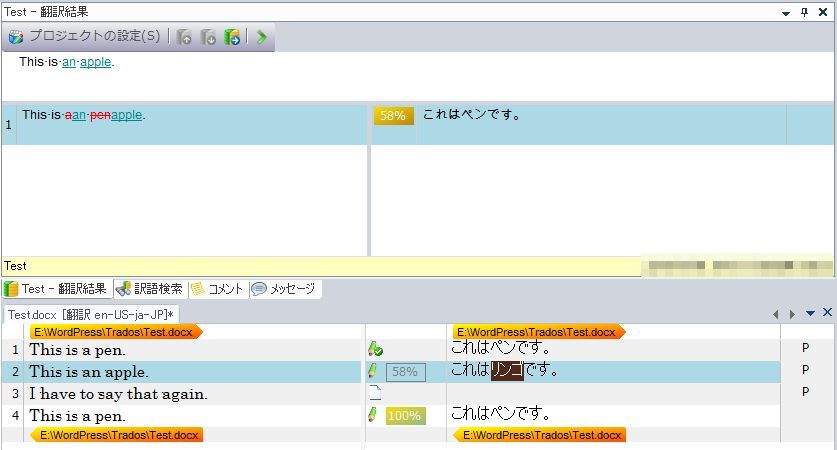
翻訳者は、翻訳メモリの内容として表示されている、この58%一致する内容を元に2行目の訳文を作成します。
この場合は、上の図のように「ペン」を「リンゴ」に編集するだけで訳文ができあがります。
3行目の翻訳
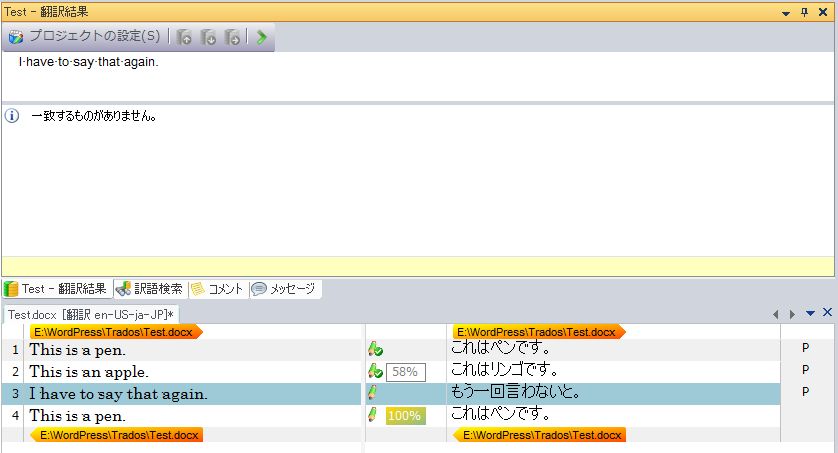
3行目については、一致する訳文や類似する訳文が翻訳メモリの中にまったくありません。
画面上に再利用できる訳文の候補が表示されていないので、一から翻訳します。
最後の行
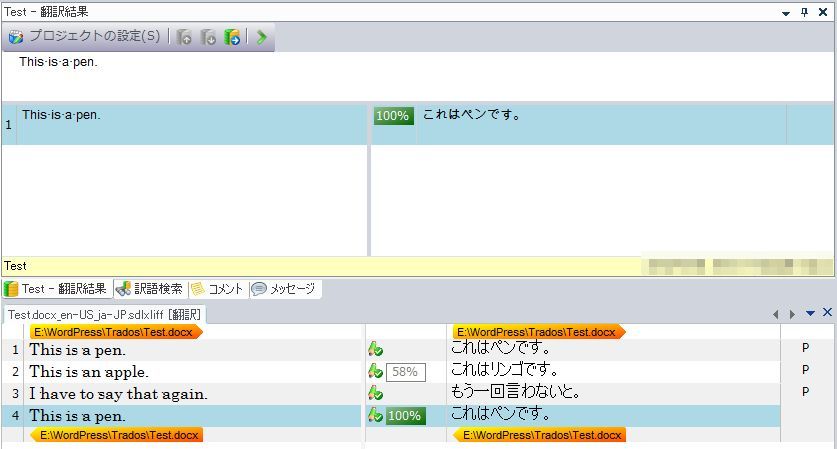
最後の行である4行目は、すでに説明したとおり、翻訳メモリの内容がコピーされているので訳文を作成する必要がありません。これで、このファイルの翻訳作業は完了です。
このように、翻訳メモリを使用した作業では、一度作成した訳文を100%再利用したり、一部を編集して部分的に再利用することで効率化を図ることができます。
機械翻訳+ポストエディットの新しい流れ
翻訳業界の機械化は、長らくこの翻訳メモリ機能を搭載した翻訳支援ツールが牽引してきました。しかし、その後、機械翻訳も利用していこうという動向が出始めました。
しかし、この機械翻訳はこれまで、品質面がかなり問題視されてきました。
原文を入れたら訳文を表示してくれる翻訳サイトを利用したことがあればすぐにわかると思いますが、支離滅裂な訳文ができあがったりして、特に昔は出力される訳文の質が低く、使い物にならないことがほとんどでした。
しかし、独自に機械翻訳の開発に取り組む企業などもあり、徐々にその精度は上がってきています。
じゃあ、機械翻訳かけて、翻訳者が手直しする?
機械翻訳の精度は年々高くなってきており、今では、短いセンテンスであれば手直しなしで使えたり、わずかな修正を加えれば使えるような訳文を出力する機械翻訳ソフトもできてきています。
そこで出てきた発想が、「少し手直しして使えるんだったら、機械翻訳かけて、それを翻訳者が手直しすれば多少効率化が図れるのでは?」といったものです。
機械翻訳を翻訳者が手直しするこのアプローチは、ポストエディットと呼ばれています。
この考え方自体に間違いはありません。ほぼそのまま、あるいは少しの手直しで使える部分があるわけですから、その部分では効率化を図ることができます。
しかし、別の部分ではさまざまな問題が指摘されています。
- センテンスが長いと結局使えない場合が多く、一から翻訳した方が早い
- 機械翻訳で出力される訳語や用字・用語が指定されたものと異なり、気づかないうちに指定された用語の使用や表記のルールを違反してしまう
- 機械翻訳された訳文を見ながら作業するため、その訳文にひきずられてしまって良い訳文ができない
- ポストエディットの作業に慣れていないと、機械翻訳の出力を編集する過程でコピペの多用やタイプミスが発生し、ケアレスミスが増える…などなど
そして現れた、翻訳メモリ+機械翻訳+ポストエディットというハイブリッドなアプローチ
機械翻訳+ポストエディットだけでは実用化・効率化が難しいなら、従来のすでに定着している翻訳メモリと併用していこう、という考え方も出てきています。
つまり、翻訳メモリに入っている訳文が使える部分はそれを使うことにして、使えない部分には機械翻訳をかけて翻訳者がポストエディットで対応するという方針です。
これはたとえば、先ほどの例であれば、1行目の「This is a pen.」や3行目の「I have to say that again.」です。
これらのセンテンスは翻訳メモリの中に一致する内容がなく、翻訳者は一から訳文を作成する必要がありました。
このような部分にはあらかじめ機械翻訳をかけておいて、翻訳作業時にその機械翻訳を利用すれば一から訳文を訳すよりも効率があがるのではないか?というのが、この作業方法の発想です。
翻訳メモリ、機械翻訳という2つの技術の連携により、それぞれ単体では効率化できない部分を補完しあってさらなる効率化を目指すアプローチということができると思います。
まとめ
翻訳メモリ、機械翻訳+ポストエディット、そしてそれらの連携による翻訳業界の機械化事情について紹介しました。
これらの技術やアプローチを導入することなく行われる翻訳も多いと思いますが、翻訳の機械化の最前線では、今回紹介した内容が活用されています。
その翻訳上の善し悪しやメリット・デメリットなどは盛んに議論されていますが、今後も機械化による効率化・合理化の試みは引き続き行われていくものと思われます。
すでに複雑な展開を見せている翻訳の機械化事情ですが、今後どうなっていくのか?というのも気になるところです。